Appearance
UnityPredict Engines
The Basics
On UnityPredict, "Engines" are the underlying compute framework that is executed, at scale, to perform inference or run business logic. Every engine must be connected to a "Model" to be usable. This is because the Model serves as the interface that defines how UnityPredict communicates with the Engine. The Model specifies variable names and data types for inputs and outputs. Unlike models, engines are always private and cannot be exposed publicly.
Users can use one of UnityPredict's code-free Engines or create a custom Engine using Python. Custom engines allow developers to write Python code, which the platform will execute at scale. These custom-defined Engines offer developers the flexibility needed to create complex AI solutions. Custom engines also get API access to some of UnityPredict's platform features such as chained-model invocation and customized inference pricing.
Finally, developers can configure the underlying hardware and software platform that their code is executed on. Lightweight models can be executed on low memory CPU configurations while large LLM models can take advantage of GPU hosting.
Creating Custom Engine(s)
Engine Management
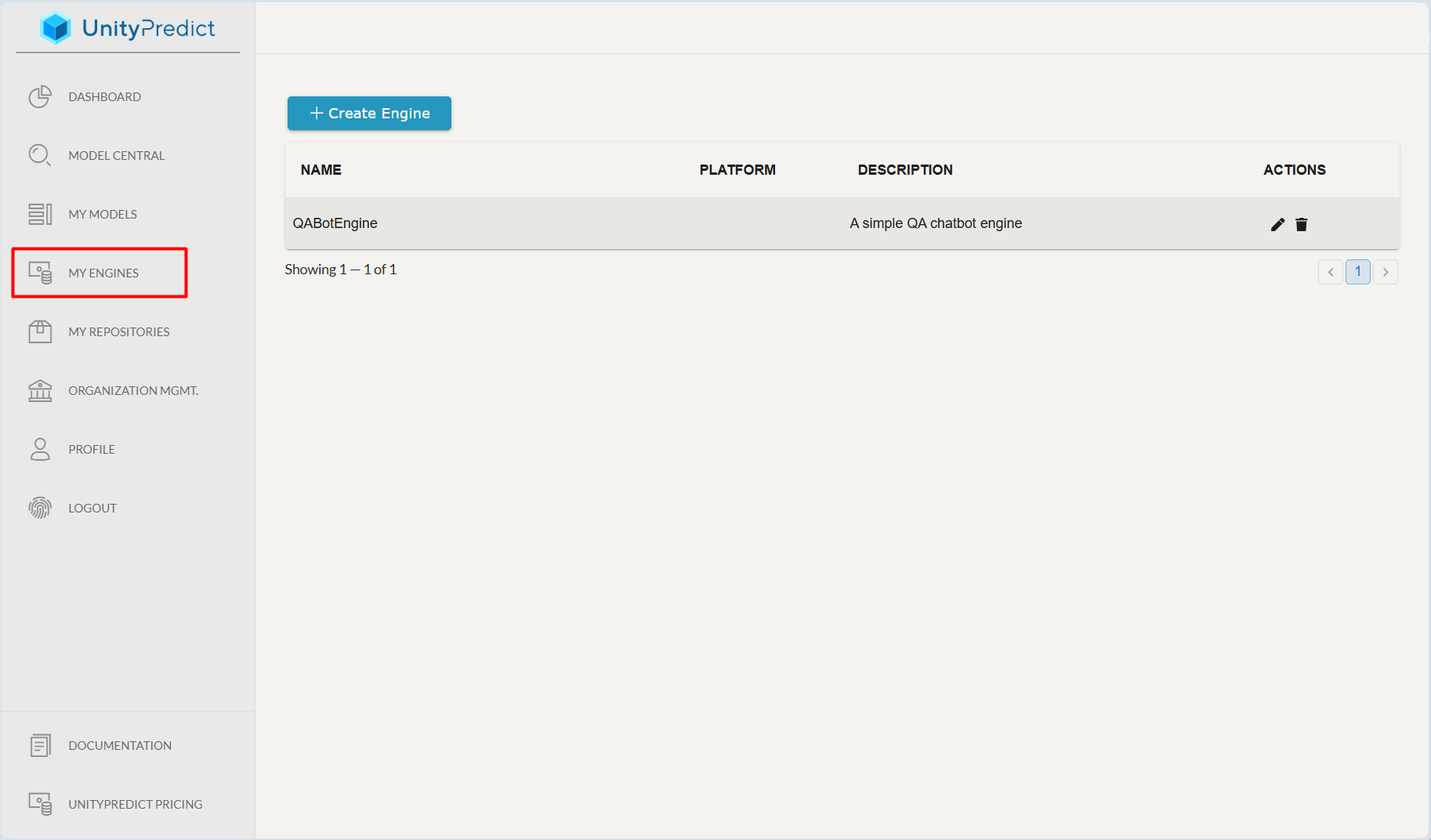
The My Engines page provides a simple interface for creating and managing custom engines.
To access the My Engines page in UnityPredict, follow these steps:
Log in to
UnityPredict: Start by logging into yourUnityPredictaccount through the official website.Navigate to the Sidebar: Once you are on the dashboard, look to the left-hand sidebar, where you will find various navigation options.
Select
My Engines: Click on theMy Enginespage located in the sidebar.
Creating a New Engine
To create a new engine, follow these steps:
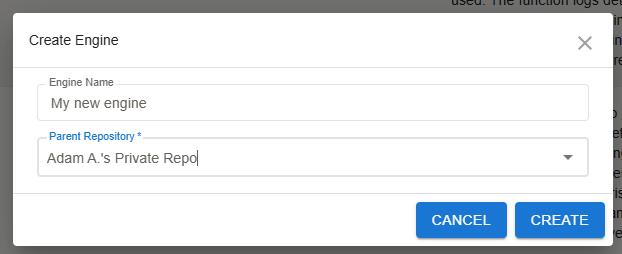
Click on the "Create Engine" Button: At the top of the page, you will see a blue button labeled
+ Create Engine. Click this button to start creating a new engine.A dialog box titled Create Engine will appear. Here, you need to provide the following details:
- Engine Name: Enter a unique name for your new engine.
- Parent Repository: Select the parent repository where this engine will be stored from the dropdown menu. Note: it is highly recommended that you choose the same repository as the model that you plan to connect this engine to.
Create the Engine: Once all required fields are filled, click the
CREATEbutton at the bottom of the dialog to create the new engine.
Engine Configuration
UnityPredict engines configuration involves two steps:
- Specifying the hosting environment (ex. platform, memory/storage requirements, etc.) and desired platform features
- Custom Python code that you want to run during inference.
Engines can also be updated and deployed using the UnityPredict SDK
Engine Details
Engine Name: Enter a unique name for your engine in the Engine Name field. This name will be used to identify your engine in the list of available engines.
Engine Description: Provide a detailed description of the engine in the Engine Description field. This description should explain the purpose and functionality of the engine.
Engine Platform: Select the appropriate platform for your engine from the Engine Platform dropdown menu. The available options include:
- CPU Lite: Python 3.8: A lightweight environment with Python 3.12. Choose this option if you don't have any dependencies or your dependencies are only lightweight packages.
- CPU: Python 3.12: A standard Python 3.12 environment. This is recommended for most use cases as it provides the best balance of performance, cost and flexibility.
- CPU: Python 3.12, C++: An extension of the regular Python 3.12 but with C++ build tools installed.
Memory Requirement: Specify the memory requirements for your engine in the Memory Requirement field. his value represents the amount of memory available to the engine.
Storage Requirement: Specify the storage requirements for your engine in the Storage Requirement field. This value represents the amount of local/temp storage available to the engine.
Save or Deploy the Engine: After filling in all the required fields, you have two options:
- Save: Click the Save button to save the engine configuration without deploying it immediately. This allows you to come back and make further changes if needed.
- Deploy: Click the Deploy button to save and deploy the engine. Once the engine is deployed, all new inferences will automatically use the new code.
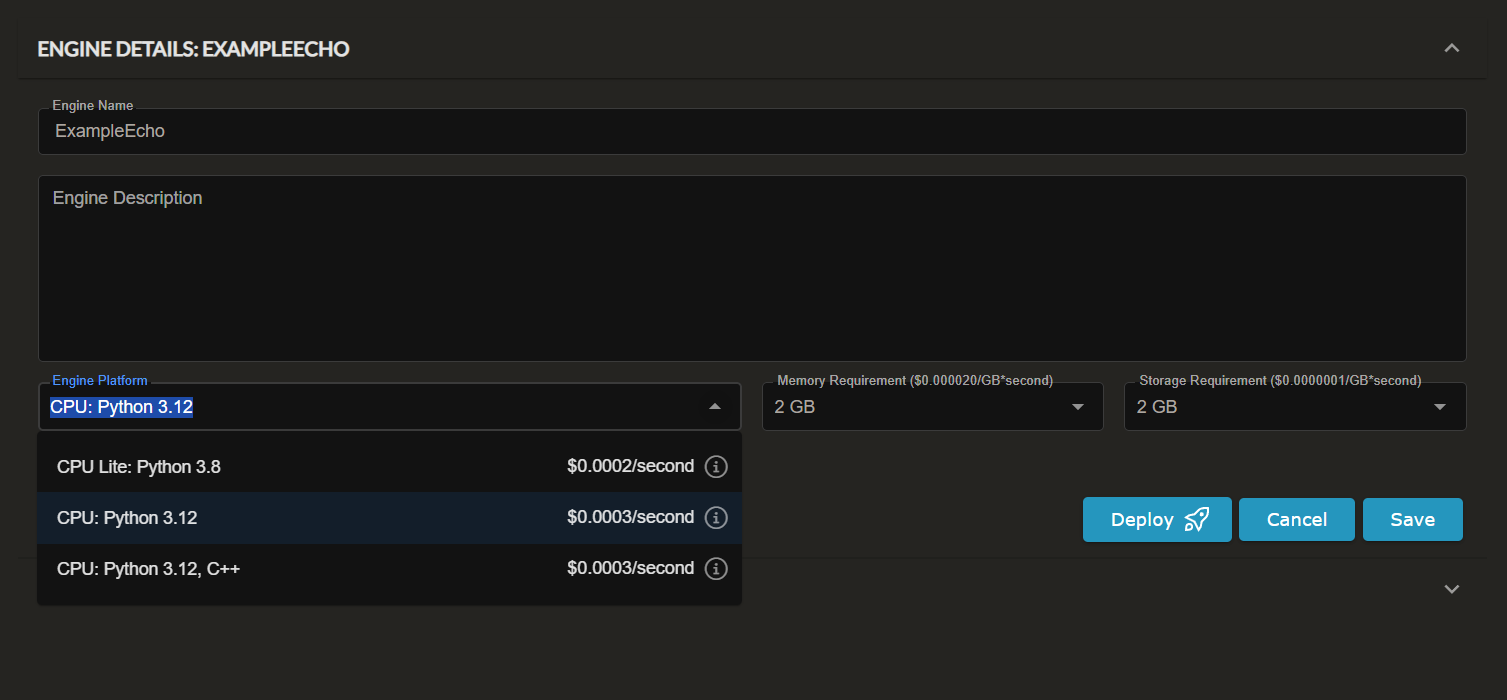
NOTE: The compute cost is calculated based on the selected Engine Platform, memory and storage requirements. T
Engine Code
In most cases, it is recommended that you use the UnityPredict SDK for managing and updating the engine code. However the web-based code editor is also provided to help accelerate small modifications and/or deployment of simple solutions.
Concepts
Every engine must have an EntryPoint.py with a run_engine function. The run_engine function is the entry point to your code.
An engine template with the function prototype for run_engine are created for you automatically when you create your engine. You can not change this function prototype (any changes will result in UnityPredict not being to launch the engine properly).
The input to run_engine is an InferenceRequest object and an instance of the UnityPredict Platform.
- The
Platformwill provide you with API access to various platform capabilities such as easy invocation of other models on the platform. - The
InferenceRequestcontains the inputs to the engine (see below for details).
The output from run_engine is an InferenceResponse object which must be initialized inside your code and returned by the function. This will be used by UnityPredict to return the proper response to the Model that is referencing the engine (see below for details).
For more details and code examples, please refer to the documentation on the UnityPredict SDK.
Web-Based Code Editor
- Source Files: The default/required Python source code files
EntryPoint.pyandPlatform.pyare automatically created. You can add additional source files as needed.EntryPoint.py: Contains the entry point to your code.Platform.py: A read-only/symbolic file that makes it easy to see the availablePlatformfunctions, models and properties.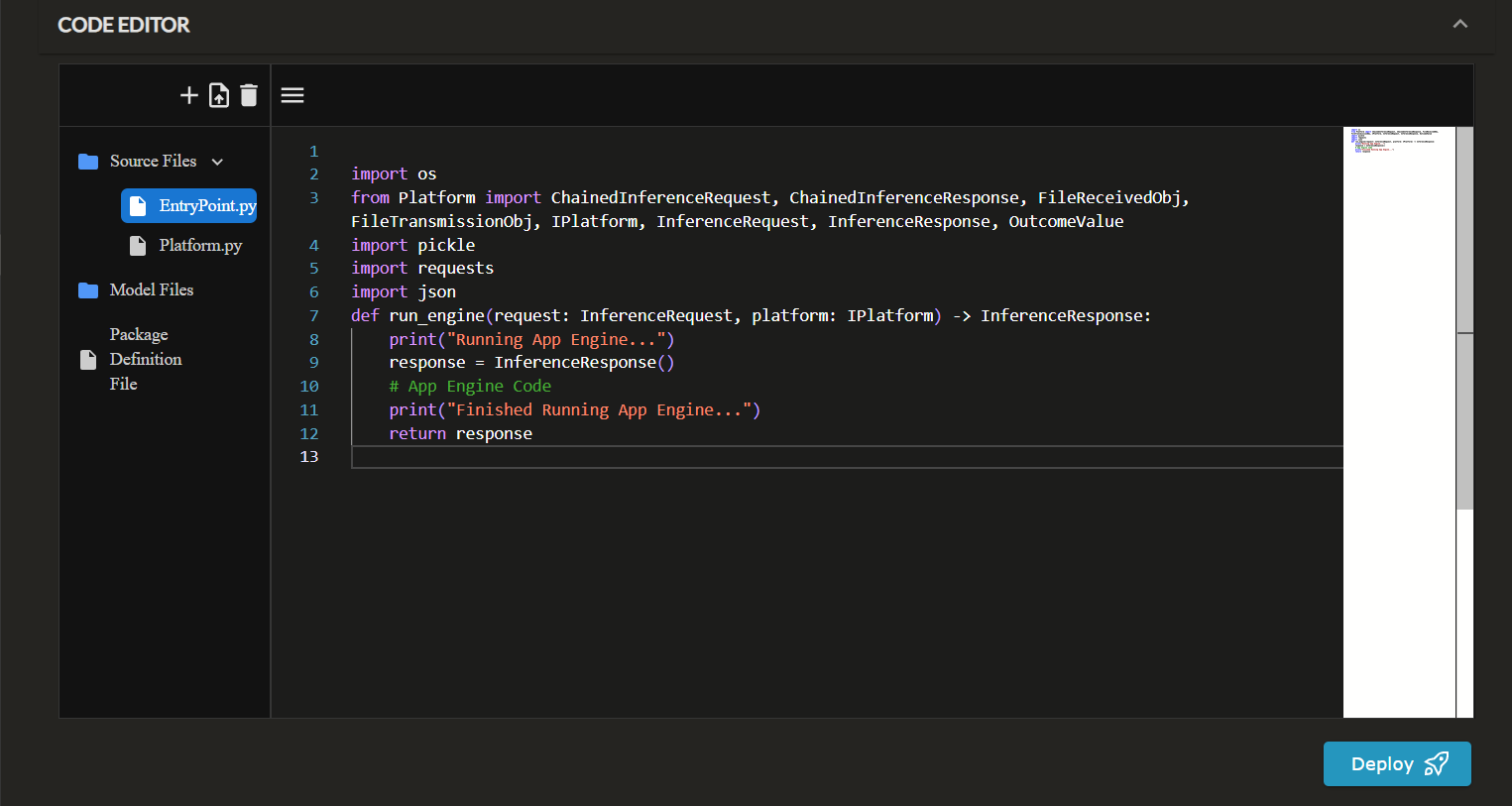
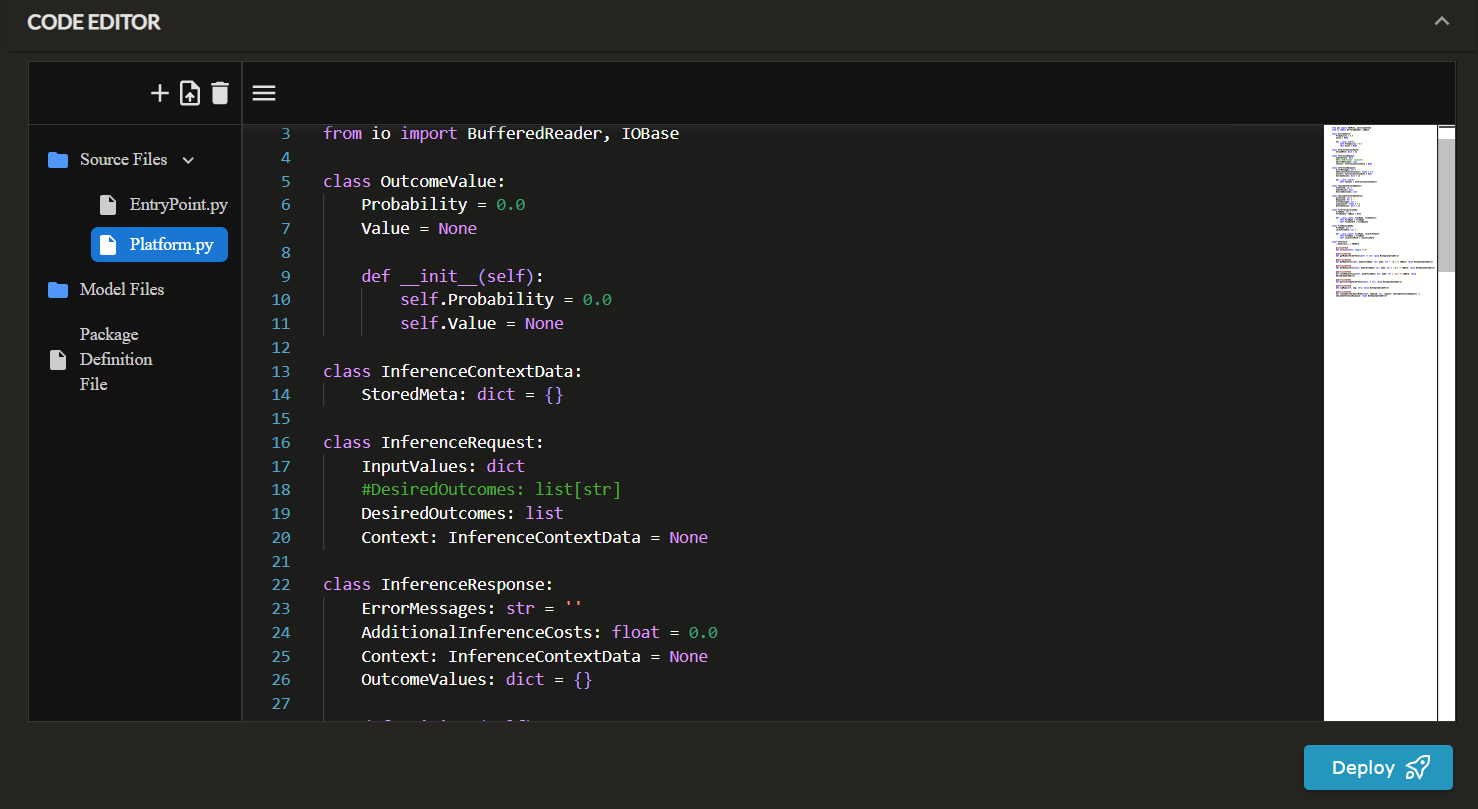
- Model Files: Any non-source code dependencies required for your engine (i.e. model files, binaries, etc.)
- Package Definition File: This is used to specify the dependencies (aka.
requirements.txt). These packages will be installed and shipped with your source code during the deployment process.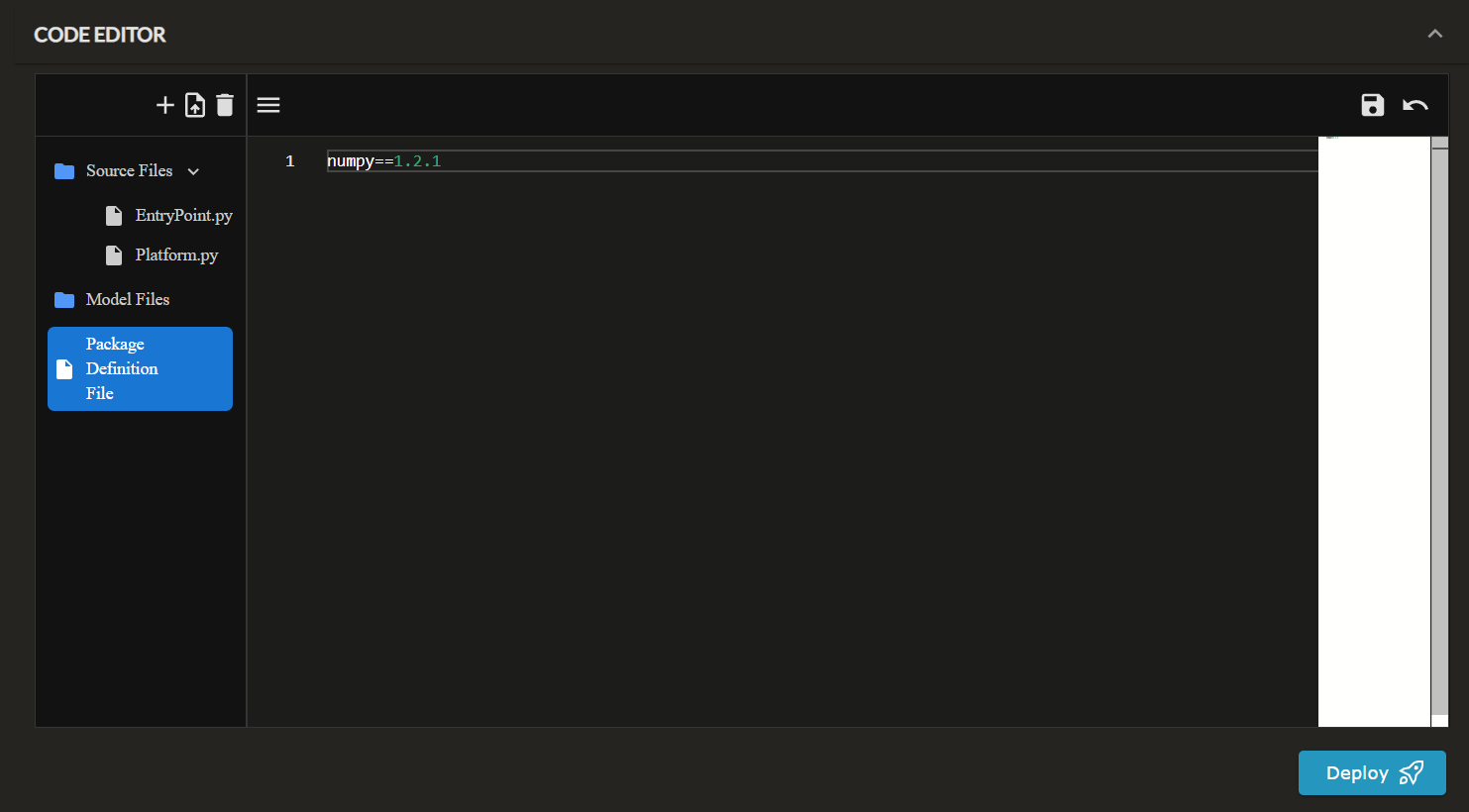
Inference Request Properties
InputValues: this is a python dictionary where the key is the input variable name (defined in the model editor) and the value is the user-provided value (i.e. through API or UI). Note: forFileobject types, this is the name of the file (the actual file data can be retrieved usingplatform.getRequestFilefunction).DesiredOutcomes: this is the list of output variable names that is being requested (defined in the model editor)Context: this is an instance ofInferenceContextDataand contains any data saved by a prior instance of the engine that was executed for the sameContextId(i.e. same user session)
Inference Response Properties
Outcomes: this is a python dictionary where the key is the output variable name (defined in the model editor) and the value is the engine-produced value which is to be sent back to the model. Note: forFileobject types, this is the name of output file (the actual file data can be saved usingplatform.saveRequestFilefunction).Context: this is an instance ofInferenceContextDataand contains any data the engine wants to save for future instances of the engine that are to be executed for the sameContextId(i.e. same user session)ReInvokeInSeconds: UnityPredict supports putting your engine intosleepmode and re-invoking it in N seconds (maximum 900 seconds). If your engine perform long-running external operations, you can use this option to save on hosting costs (UnityPredict is serverless so you only pay for second of compute when your engine is running). Keep in mind that you will need to use theContextto save the state (i.e. information about prior runs) to avoid your engine running forever.ErrorMessages: a flag string value containing error messages that you want to report back to the model user (i.e. through UI or API).AdditionalInferenceCosts: a floating point value representing any costs you want to charge to the model user.
Platform Functions & Properties
The underlying hosting infrastructure for engines can vary significantly depending on the Engine Platform that you select. It can also change at any time as UnityPredict makes performance improvements and upgrades on a regular basis. Platform functions are designed to provide a stable, hardware & software independent interface for common operations within UnityPredict.
- Function
getModelsFolderPath: This function returns the local/temp path for all model files uploaded for this engine - Function
getModelFile: Returns an IOBase object for easily reading a model file, provided the model file name - Function
getRequestFile: Returns an IOBase object for reading a request file (used for inputs). Request files are files that are meant to travel between the engine and the consuming model (this includes being returned by the API or shown in the UI). Request files include any input or output variable withFiledata type. - Function
saveRequestFile: Returns an IOBase object for writing a request file (used for engine-generated outputs). Request files are files that are meant to travel between the engine and the consuming model (this includes being returned by the API or shown in the UI). Request files include any input or output variable withFiledata type. - Function
getRequestFilePublicUrl: This platform function returns a temporary public URL for any request file. When this is used, UnityPredict will automatically upload the request file to a server and generate a secure, temporary url for reading the file (expired after 12 hours). This function can be useful if you are trying to perform operations with tools (or external APIs) that don't support file upload and require a publicly accessible link. - Function
getLocalTempFolderPath: Provides the path to a temp folder within the local file system with read/write permissions. - Function
logMsg: Allows writing debug logs that can be read in the UI by the model developer (these are only visible to the model developer). - Function
invokeUnityPredictModel: Provides a very simple, single-line invocation operation for running other models on the platform. This function is specifically designed to allow developers to easily chain multiple ML models together to create more complex solutions. In order to use this operation, you must have enabledChained Modelsunder theEngine Detailssection.
Understanding Engine Components
The run_engine Function
Every custom Engine must implement a function named run_engine, which serves as the entry point:
python
def run_engine(request: InferenceRequest, platform: IPlatform) -> InferenceResponse:This function receives:
request(InferenceRequest) – Contains input values and metadataplatform(IPlatform) – Provides API access to UnityPredict services
It returns:
response(InferenceResponse) – The result of inference
Handling Input Values
- Inputs are accessed via
request.InputValues InputValuesis a dictionary containing the model inputs that are passed to the engine, whether they come from the UnityPredict UI or API calls- The keys in this dictionary correspond to the input variable names defined in your model
- Example:
python
input_value = request.InputValues.get("InputValue", 0)Generating Predictions
- AI logic is executed inside
run_engine() - Example:
python
output_value = input_value * 2Returning Output Values
- Outputs must be stored in
response.Outcomesas arrays - Multiple values can be returned for a single variable by adding multiple
OutcomeValueobjects to the array - Example:
python
# Single value
response.Outcomes["OutputValue"] = [OutcomeValue(output_value)]
# Multiple values
response.Outcomes["OutputValue"] = [
OutcomeValue(output_value1),
OutcomeValue(output_value2),
OutcomeValue(output_value3)
]Logging Messages
Use platform.logMsg() for debugging. These logs are only visible to the model developer and not to end users:
python
platform.logMsg("Processing input data...")Using AdditionalInferenceCosts
UnityPredict allows developers to charge additional costs for model inference using AdditionalInferenceCosts. This is useful for metering usage based on resource consumption or passing through costs from external services that your engine uses.
Example: Adding Fixed Compute Cost
python
response.AdditionalInferenceCosts = 0.01 # Charge $0.01 for this inferenceExample: Dynamic Cost Calculation
If your engine processes large files or performs complex operations, you may want to adjust the cost dynamically based on the input:
python
compute_time_seconds = 10 # Example compute time
cost_per_second = 0.002 # Example cost rate
external_api_cost = 0.05 # Cost from external API call
response.AdditionalInferenceCosts = (compute_time_seconds * cost_per_second) + external_api_costWhen to Use AdditionalInferenceCosts
✅ Charge users based on processing time
✅ Adjust pricing based on file size or resource consumption
✅ Pass through costs from external APIs or services
✅ Apply premium service costs for enhanced model accuracy or performance
Handling Context & Stateful Inference
Some AI models need to maintain state between invocations. When context is enabled on a model, UnityPredict maintains the engine's context data across multiple invocations within the same user session. This makes it possible to store things like chat history, user preferences, or other historical data that needs to persist between calls.
Using Context Storage
python
# Read from previous context (if any)
context = request.Context.StoredMeta
previous_chat_history = context.get("chat_history", "[]") # Returns string, default empty array
# Update the context with new data
import json
chat_history = json.loads(previous_chat_history)
chat_history.append("New message")
context["chat_history"] = json.dumps(chat_history) # Store as JSON string
# Save context for future invocations
response.Context.StoredMeta = contextReinvoking the Engine
For long-running tasks, you can tell UnityPredict to pause execution and retry later. The context will be preserved during this pause:
python
response.ReInvokeInSeconds = 30 # Pause for 30 secondsThis tells UnityPredict to pause execution for 30 seconds before retrying. Since UnityPredict is serverless, you only pay for compute time when your engine is actively running. If your engine performs long-running external operations, you can use ReInvokeInSeconds to pause the engine and save on hosting costs during the waiting period. The stored context will be available when the engine resumes. Keep in mind that you will need to use the Context to save the state (i.e. information about prior runs) to avoid your engine running forever.
Receiving Files as Input
UnityPredict allows file inputs to be processed within an engine. Files are provided as request file objects and must be retrieved using platform.getRequestFile().
Example: Handling a Text File Input
python
from unitypredict_engines import IPlatform, InferenceRequest, InferenceResponse, OutcomeValue
def run_engine(request: InferenceRequest, platform: IPlatform) -> InferenceResponse:
"""
A UnityPredict engine that reads an uploaded text file, counts the number of words, and returns the count.
"""
platform.logMsg("Running File Processing Engine...\n")
# Initialize response
response = InferenceResponse()
# Get the file name from the request input
file_name = request.InputValues.get("UploadedFile", "")
if not file_name:
response.ErrorMessages = "No file provided."
platform.logMsg(response.ErrorMessages)
return response
try:
# Retrieve the file as a readable stream
with platform.getRequestFile(file_name, "r") as file:
content = file.read()
# Perform processing (count words in file)
word_count = len(content.split())
# Store the result in response
response.Outcomes["WordCount"] = [OutcomeValue(word_count)]
platform.logMsg(f"Processed file '{file_name}', Word Count: {word_count}")
except Exception as e:
response.ErrorMessages = f"Error processing file: {str(e)}"
platform.logMsg(response.ErrorMessages)
return responseHow This Works:
- The engine retrieves the file name from
request.InputValues - It then opens the file using
platform.getRequestFile() - The content is read, processed (word count), and stored in
response.Outcomes
Outputting Files as a Result
Engines in UnityPredict can generate and return files as output. This is useful for models that produce reports, processed images, or other types of file-based results.
Example: Generating and Returning a Text File
python
from unitypredict_engines import IPlatform, InferenceRequest, InferenceResponse, OutcomeValue
def run_engine(request: InferenceRequest, platform: IPlatform) -> InferenceResponse:
"""
A UnityPredict engine that takes an input string and writes it to an output text file.
"""
platform.logMsg("Running File Output Engine...\n")
# Initialize response
response = InferenceResponse()
# Get input text from request
input_text = request.InputValues.get("TextInput", "")
if not input_text:
response.ErrorMessages = "No input text provided."
platform.logMsg(response.ErrorMessages)
return response
try:
# Define output file name
output_file_name = "OutputTextFile.txt"
# Write content to output file
with platform.saveRequestFile(output_file_name, "w") as output_file:
output_file.write(input_text)
# Store the output file name in response
response.Outcomes["GeneratedFile"] = [OutcomeValue(output_file_name)]
platform.logMsg(f"Generated file: {output_file_name}")
except Exception as e:
response.ErrorMessages = f"Error generating file: {str(e)}"
platform.logMsg(response.ErrorMessages)
return responseHow This Works:
The engine retrieves the input text from
request.InputValuesIt creates a text file using
platform.saveRequestFile()The content is written to the file
The file name is returned as output in
response.OutcomesRetrieving Generated Output Files: Once an engine generates an output file, users can download the file through two different methods:
A. UnityPredict Auto-Generated UI
- If the model linked to the engine has an auto-generated web UI, the output file will be displayed in the UI after inference completes
- Users can simply click a download button next to the output file name to retrieve it
B. UnityPredict Auto-Generated API
- Every model in UnityPredict has a REST API that can be used to retrieve output files programmatically
- The output file name will be returned in the API response under Outcomes, and users can then use the UnityPredict download API to fetch the file
Chained Invocations in UnityPredict
UnityPredict supports model chaining, allowing developers to invoke other models directly from within an engine. This feature enables engines to leverage multiple models for more complex AI workflows.
This section of the guide explains how to use chained invocations inside your engine code, with examples demonstrating how to:
- Call an external UnityPredict model
- Pass inputs and receive outputs from chained models
- Integrate the results back into your engine
Understanding Chained Inference
When chaining models:
- Each model has a unique ID, which is used to invoke it
- Inputs and outputs are passed between models using
ChainedInferenceRequestandChainedInferenceResponse - File transmission is supported for cases where models generate or process files
Example: Chained Model Invocation
Creating an SRT File from an Audio File
In this example, we invoke a speech-to-text model to generate subtitles (SRT file) from an audio file.
python
def CreateSRT(audioFilePath: str, platform: IPlatform):
platform.logMsg('Creating SRT File!\n')
chainedModelResponse: ChainedInferenceResponse = platform.invokeUnityPredictModel(
'6327eea5-27e5-47ec-9a10-d926dfcc3502',
ChainedInferenceRequest(
inputValues = {
'Audio File': FileTransmissionObj('Speech.mp3', open(audioFilePath, 'rb')),
'Language Code': 'en-US'
},
desiredOutcomes = ['Captions']
)
)
print(chainedModelResponse)
outputFile: FileReceivedObj = chainedModelResponse.getOutputValue('Captions')
return outputFile.LocalFilePathBreaking It Down
- The ChainedInferenceRequest is initialized
- Input values (
Audio FileandLanguage Code) are set - Desired output is set to
Captions - The invokeUnityPredictModel() function calls another model (
6327eea5-27e5-47ec-9a10-d926dfcc3502) - The resulting SRT file is returned as
LocalFilePath
Full Example: Using Chained Model in an Engine
This example demonstrates using the speech-to-text model inside a full engine execution flow.
python
from unitypredict_engines import IPlatform, InferenceRequest, InferenceResponse, OutcomeValue
import os
import shutil
def CreateSRT(audioFilePath: str, platform: IPlatform):
platform.logMsg('Creating SRT File!\n')
chainedModelResponse: ChainedInferenceResponse = platform.invokeUnityPredictModel(
'6327eea5-27e5-47ec-9a10-d926dfcc3502',
ChainedInferenceRequest(
inputValues = {
'Audio File': FileTransmissionObj('Speech.mp3', open(audioFilePath, 'rb')),
'Language Code': 'en-US'
},
desiredOutcomes = ['Captions']
)
)
print(chainedModelResponse)
outputFile: FileReceivedObj = chainedModelResponse.getOutputValue('Captions')
return outputFile.LocalFilePath
def run_engine(request: InferenceRequest, platform: IPlatform) -> InferenceResponse:
platform.logMsg("Running User Code...")
result = InferenceResponse()
audioFile = request.InputValues['Audio File']
# Copy input audio file to local temp folder
localAudioFilePath = os.path.join(platform.getLocalTempFolderPath(), "audio.mp3")
shutil.copyfileobj(platform.getRequestFile(audioFile, 'rb'), open(localAudioFilePath, 'wb'))
# Generate subtitles (SRT file) for the audio
localSRTFilePath = CreateSRT(localAudioFilePath, platform)
platform.logMsg('Created SRT File!\n')
# Copy the SRT file to a request file that can be returned to the user
shutil.copyfileobj(open(localSRTFilePath, 'rb'), platform.saveRequestFile('subtitles.srt', 'wb'))
result.Outcomes['Generated SRT File'] = [OutcomeValue('subtitles.srt')]
platform.logMsg("Finished Running User Code...")
return resultBy leveraging model chaining, developers can build sophisticated AI pipelines inside UnityPredict, efficiently linking models for powerful AI workflows. 🚀